Natural language processing (NLP) A Comprehensive Overview
Natural language processing (NLP) unveils the fascinating intersection of computer science and linguistics, enabling machines to understand, interpret, and generate human language. This field has witnessed remarkable advancements, progressing from rudimentary rule-based systems to sophisticated deep learning models capable of nuanced language comprehension. From translating languages to analyzing sentiment in social media, NLP’s applications are vast and ever-expanding, impacting numerous sectors and reshaping how we interact with technology.
This exploration delves into the core concepts, techniques, and applications of NLP, examining its historical trajectory, algorithmic foundations, and ethical considerations. We’ll investigate various NLP tasks, analyze the challenges inherent in processing ambiguous language, and consider the future potential of this transformative technology. The discussion will also include a detailed example of sentiment analysis, illustrating the practical application of NLP principles.




Introduction to Natural Language Processing (NLP)
Source: datasciencedojo.com
Natural Language Processing (NLP) is a branch of artificial intelligence (AI) that focuses on enabling computers to understand, interpret, and generate human language. This involves bridging the gap between human communication and computer understanding, allowing machines to process and analyze vast amounts of textual and spoken data. The ultimate goal is to create systems that can interact with humans naturally and meaningfully, performing tasks that typically require human intelligence.
NLP has a wide range of applications across various industries. From powering virtual assistants like Siri and Alexa to enabling accurate machine translation services like Google Translate, its impact is pervasive. In healthcare, NLP helps analyze medical records to improve diagnosis and treatment; in finance, it assists in fraud detection and risk assessment; and in marketing, it analyzes customer feedback to improve products and services.
The applications are virtually limitless, driven by the ever-increasing availability of textual data and advancements in machine learning techniques.
A Brief History of NLP
The field of NLP has its roots in the mid-20th century, with early work focusing on rule-based systems. These systems relied on manually crafted rules to analyze and process language, which proved to be both time-consuming and limited in their ability to handle the complexities of human language. The 1980s and 1990s saw a shift towards statistical methods, leveraging large datasets to train models capable of learning patterns and relationships in language.
This statistical approach marked a significant improvement, allowing for more robust and adaptable systems. The advent of deep learning in the 2010s revolutionized the field, leading to significant breakthroughs in tasks such as machine translation and speech recognition. Deep learning models, particularly recurrent neural networks (RNNs) and transformers, have demonstrated remarkable capabilities in understanding and generating human-like text.
Key milestones include the development of the first successful machine translation systems, the creation of powerful language models like BERT and GPT-3, and the increasing accuracy of sentiment analysis tools.
Types of NLP Tasks
NLP encompasses a wide array of tasks, each addressing different aspects of language processing. Some prominent examples include:
Text Classification: This involves assigning predefined categories to text documents. For example, classifying emails as spam or not spam, or news articles as belonging to specific topics (sports, politics, etc.).
Machine Translation: This focuses on automatically translating text from one language to another. Google Translate is a prime example, utilizing sophisticated NLP techniques to achieve accurate and fluent translations.
Sentiment Analysis: This aims to determine the emotional tone expressed in text, whether it’s positive, negative, or neutral. This is widely used in social media monitoring, brand reputation management, and customer feedback analysis.
Named Entity Recognition (NER): This involves identifying and classifying named entities in text, such as people, organizations, locations, and dates. This is crucial for information extraction and knowledge base construction.
Part-of-Speech (POS) Tagging: This task assigns grammatical tags to words in a sentence, indicating their role (noun, verb, adjective, etc.). This is a foundational step in many NLP pipelines.
Comparison of NLP Approaches
Different approaches exist for tackling NLP problems, each with its own strengths and weaknesses. The following table summarizes some key differences:
| Approach | Description | Strengths | Weaknesses |
|---|---|---|---|
| Rule-based | Relies on manually defined linguistic rules. | Transparent and easily interpretable. | Difficult to scale, brittle to variations in language. |
| Statistical | Uses statistical models trained on large datasets. | More robust and adaptable than rule-based approaches. | Requires large amounts of training data, may not capture subtle linguistic nuances. |
| Deep Learning | Employs deep neural networks to learn complex patterns in language. | State-of-the-art performance on many NLP tasks. | Requires significant computational resources, can be difficult to interpret. |
NLP Techniques and Algorithms
Natural Language Processing (NLP) leverages a diverse range of techniques and algorithms to understand, interpret, and generate human language. These methods span statistical models, machine learning approaches, and increasingly, deep learning architectures. The choice of algorithm often depends on the specific NLP task and the available data.
Hidden Markov Models (HMMs) in NLP
Hidden Markov Models are probabilistic graphical models particularly well-suited for tasks involving sequential data, such as part-of-speech tagging and speech recognition. An HMM defines a system with hidden states (e.g., grammatical tags) and observable emissions (e.g., words). The model learns the probabilities of transitioning between hidden states and emitting specific observations from each state. This allows the model to predict the most likely sequence of hidden states given a sequence of observed words.
For instance, in part-of-speech tagging, an HMM can learn the probabilities of transitioning from a noun to a verb and the probability of observing specific words given each part-of-speech tag. The Viterbi algorithm is commonly used for finding the most likely sequence of hidden states.
Recurrent Neural Networks (RNNs) in NLP
Recurrent Neural Networks are a type of neural network designed to handle sequential data effectively. Unlike feedforward neural networks, RNNs possess internal memory, allowing them to consider previous inputs when processing current input. This makes them particularly useful for NLP tasks involving sequences, such as machine translation, text summarization, and sentiment analysis. Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) are advanced RNN architectures that address the vanishing gradient problem, allowing them to learn long-range dependencies in sequences.
For example, in machine translation, an RNN can process the source sentence word by word, maintaining a representation of the sentence’s meaning in its internal state, and then generate the target sentence based on this internal representation.
Word Embeddings: Word2Vec and GloVe
Word embeddings represent words as dense, low-dimensional vectors, capturing semantic relationships between words. Words with similar meanings have vectors that are close together in the vector space. Word2Vec and GloVe are two popular algorithms for generating word embeddings. Word2Vec uses either the Continuous Bag-of-Words (CBOW) or Skip-gram model to learn embeddings by predicting surrounding words from a target word or vice-versa.
GloVe, on the other hand, leverages global word-word co-occurrence statistics to learn embeddings. These embeddings are then used as input features in various NLP tasks, significantly improving performance. For example, using pre-trained word embeddings like Word2Vec or GloVe can lead to better accuracy in sentiment analysis or text classification tasks.
Handling Ambiguity in Natural Language
Natural language is inherently ambiguous; a single sentence can have multiple interpretations depending on context and world knowledge. Different approaches exist to address this ambiguity. Statistical methods, like those used in HMMs, rely on probabilities to determine the most likely interpretation. Syntactic parsing, which involves analyzing the grammatical structure of a sentence, can help disambiguate meaning by identifying the relationships between words.
Semantic analysis, which focuses on the meaning of words and sentences, can further refine interpretations by leveraging world knowledge and context. Disambiguation often involves a combination of these techniques, employing multiple methods to resolve ambiguities and improve the accuracy of NLP systems. For instance, a system might use part-of-speech tagging to identify the role of each word, syntactic parsing to understand the sentence structure, and semantic analysis to resolve any remaining ambiguity based on context.
Sentiment Analysis Pipeline
The following flowchart illustrates the steps involved in a sentiment analysis pipeline:[Description of Flowchart: The flowchart begins with “Text Input,” followed by “Text Preprocessing” (cleaning, tokenization, stemming/lemmatization), then “Feature Extraction” (e.g., using word embeddings or TF-IDF), followed by “Sentiment Classification” (using a machine learning model like a Naive Bayes classifier or an RNN), and finally “Sentiment Output” (positive, negative, or neutral).] Each step involves specific algorithms and techniques; the choice of algorithm for each step depends on the desired level of accuracy and the available resources.
For example, the preprocessing step might involve removing punctuation, converting text to lowercase, and handling special characters. Feature extraction could involve calculating term frequencies or generating word embeddings. Finally, sentiment classification would use a trained model to predict the sentiment of the text. A real-world example of this would be analyzing customer reviews for a product to gauge overall customer satisfaction.
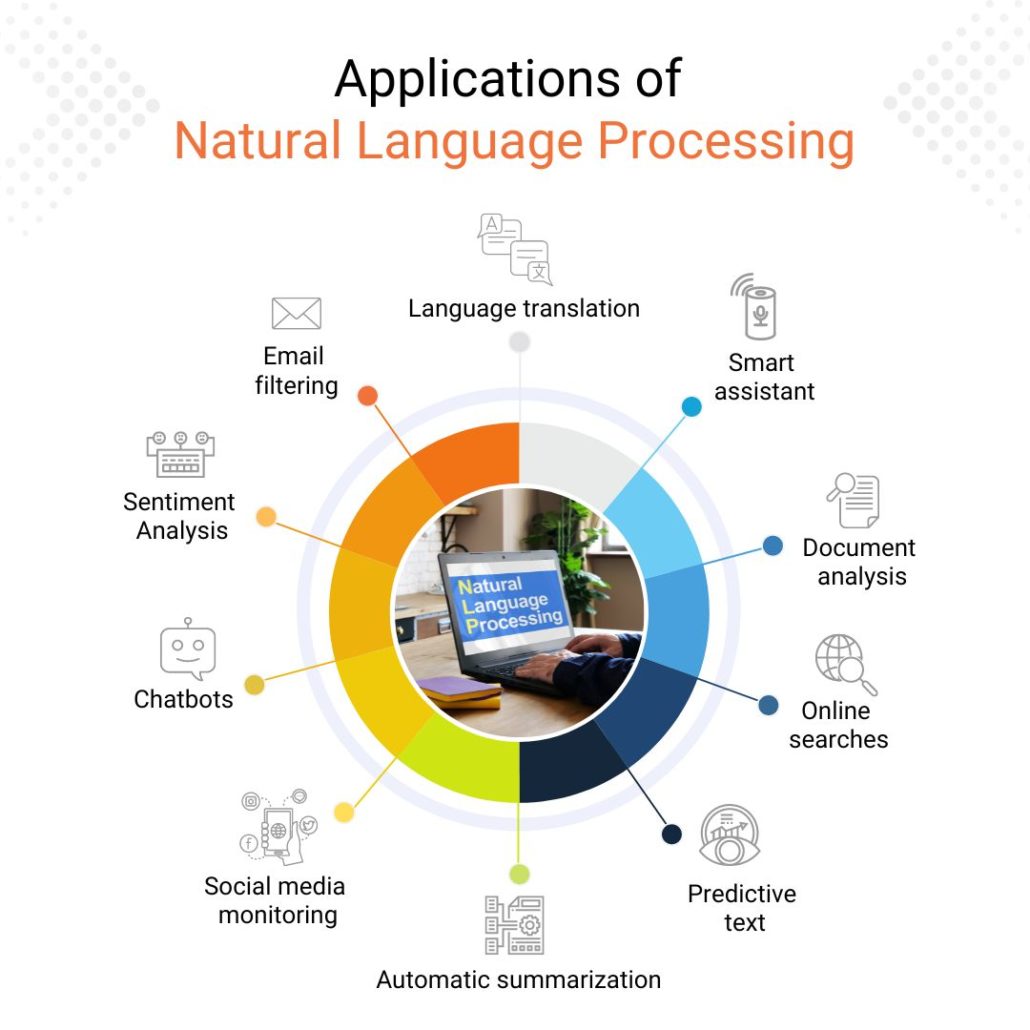
Applications of NLP
Natural Language Processing (NLP) has rapidly evolved from a niche research area to a transformative technology impacting numerous sectors. Its ability to understand, interpret, and generate human language opens doors to automation, improved efficiency, and data-driven decision-making across diverse fields. This section explores some key applications of NLP, highlighting both the opportunities and challenges presented.
NLP in Healthcare
NLP is revolutionizing healthcare through improved diagnostics, patient care, and administrative efficiency. For example, NLP algorithms can analyze patient medical records to identify patterns and risk factors for specific diseases, enabling proactive interventions and personalized treatment plans. Furthermore, NLP powers chatbots that provide patients with 24/7 access to medical information and appointment scheduling, reducing the burden on healthcare staff.
Challenges include ensuring data privacy and security, as well as addressing biases in algorithms that could lead to inaccurate diagnoses or discriminatory treatment. Opportunities lie in developing more sophisticated NLP models capable of understanding complex medical terminology and reasoning, ultimately leading to better patient outcomes and more efficient healthcare systems. The improved speed and accuracy of processing medical records, for example, can drastically reduce administrative workloads and free up clinicians to focus on patient care.
NLP in Finance
The financial industry leverages NLP for tasks ranging from fraud detection to sentiment analysis of market trends. NLP algorithms can analyze vast amounts of financial news, social media posts, and company reports to identify potential risks and opportunities. Sentiment analysis, for instance, helps assess investor confidence and predict market movements. However, challenges include the complexity and volatility of financial data, as well as the need to ensure the accuracy and reliability of NLP-driven predictions.
Opportunities lie in developing more robust and explainable NLP models that can help financial institutions make better investment decisions and mitigate risks more effectively. For example, real-time sentiment analysis of news articles can trigger automated trading strategies, optimizing investment portfolios based on market shifts.
NLP in Customer Service
NLP is transforming customer service through the development of intelligent chatbots and virtual assistants. These systems can handle routine customer inquiries, provide personalized recommendations, and resolve simple issues without human intervention, freeing up human agents to focus on more complex problems. Challenges include the need to create chatbots that can understand the nuances of human language and handle unexpected or emotional customer interactions.
Opportunities lie in developing more empathetic and human-like chatbots capable of providing a seamless and personalized customer experience. For instance, an e-commerce company using NLP-powered chatbots can improve customer satisfaction by providing immediate answers to frequently asked questions, reducing wait times and improving overall efficiency.
Real-World NLP Applications and Their Impact
The following list showcases the breadth of NLP’s impact across various sectors:
- Machine Translation: Facilitates communication across languages, breaking down global barriers in business and education. Impact: Increased global collaboration and accessibility of information.
- Spam Detection: Filters out unwanted emails, protecting users from phishing scams and malware. Impact: Enhanced cybersecurity and improved email management.
- Social Media Monitoring: Analyzes public sentiment towards brands and products, providing valuable insights for marketing and public relations. Impact: Improved brand reputation management and targeted marketing campaigns.
- Legal Document Review: Automates the process of reviewing large volumes of legal documents, improving efficiency and reducing costs for law firms. Impact: Faster and more cost-effective legal processes.
Ethical Considerations in NLP
The rapid advancement of Natural Language Processing (NLP) presents significant ethical challenges. While offering transformative potential across various sectors, the inherent biases within data and algorithms, coupled with privacy concerns and the potential for misuse, necessitate a careful and responsible approach to development and deployment. Addressing these ethical considerations is crucial to ensure NLP benefits society equitably and avoids exacerbating existing inequalities.
Bias in NLP Models and Datasets
NLP models are trained on vast datasets, and if these datasets reflect societal biases (e.g., gender, racial, socioeconomic), the resulting models will inevitably perpetuate and even amplify those biases. For example, a sentiment analysis model trained primarily on data from Western cultures might misinterpret the nuances of language and sentiment in other cultures, leading to inaccurate or unfair assessments.
Similarly, a resume-screening tool trained on historical hiring data might inadvertently discriminate against certain demographic groups if past hiring practices were biased. This bias can manifest in various ways, from skewed predictions to the reinforcement of harmful stereotypes. Mitigating this requires careful curation of training data, algorithmic fairness techniques, and ongoing monitoring for bias in model outputs.
Implications of NLP for Privacy and Security, Natural language processing (NLP)
NLP systems often process sensitive personal information, raising significant privacy concerns. Chatbots, for instance, may collect and analyze user conversations, potentially revealing private details or opinions. Similarly, NLP-powered surveillance technologies can track individuals’ online activities and communications, raising concerns about government overreach and potential abuse. Security risks also arise from the vulnerability of NLP models to adversarial attacks, where malicious actors manipulate input data to elicit unintended or harmful outputs.
This could lead to the spread of misinformation, identity theft, or other forms of cybercrime. Robust security measures, data anonymization techniques, and transparent data usage policies are crucial to address these risks.
Examples of NLP Misuse and Unintended Consequences
The potential for NLP misuse is considerable. Deepfakes, generated using sophisticated NLP techniques, can be used to create convincing but false audio or video recordings, potentially damaging reputations or influencing elections. Similarly, NLP-powered chatbots can be used to spread misinformation or propaganda at scale, manipulating public opinion and undermining trust in legitimate sources of information. The automated generation of hate speech or discriminatory content is another significant concern.
The Cambridge Analytica scandal, though not solely reliant on NLP, highlighted the potential for large-scale data misuse in influencing public opinion. These examples underscore the need for responsible development and deployment of NLP technologies, accompanied by robust oversight and regulatory frameworks.
Ethical Guidelines for Developing and Deploying NLP Systems
The responsible development and deployment of NLP systems necessitate a clear set of ethical guidelines. These should include:
- Prioritizing fairness and avoiding bias in data collection and model training.
- Ensuring transparency and accountability in algorithmic decision-making.
- Protecting user privacy and data security through robust measures.
- Implementing mechanisms for detecting and mitigating unintended consequences.
- Promoting human oversight and control in the deployment of NLP systems.
- Establishing clear ethical review processes for NLP projects.
- Fostering collaboration between researchers, developers, and policymakers to address ethical challenges.
Future Trends in NLP
Natural Language Processing (NLP) is a rapidly evolving field, constantly pushing the boundaries of what’s possible in human-computer interaction. Driven by advancements in computing power and innovative algorithmic approaches, the future of NLP promises transformative changes across various sectors. This section explores some key emerging trends and their potential societal impact.The convergence of deep learning and transfer learning is significantly accelerating NLP’s progress.
Deep learning models, particularly those based on neural networks, have proven exceptionally adept at capturing complex patterns in language data. Transfer learning, which involves leveraging knowledge gained from one task to improve performance on another, allows for the development of more robust and efficient NLP systems, especially when dealing with limited data for specific languages or domains. This has led to breakthroughs in areas such as machine translation and sentiment analysis, with models exhibiting near-human-level performance in certain tasks.
Advancements in Deep Learning and Transfer Learning
Deep learning architectures, such as transformers, have revolutionized NLP. Transformers, with their self-attention mechanisms, excel at capturing long-range dependencies within sentences, leading to significant improvements in tasks like machine translation and text summarization. Google’s BERT (Bidirectional Encoder Representations from Transformers) is a prime example of a highly successful transformer-based model that has become a benchmark for many NLP tasks.
Transfer learning techniques, such as fine-tuning pre-trained models like BERT on specific datasets, have dramatically reduced the need for massive amounts of labeled data, making NLP accessible to a wider range of applications and languages. This has led to a democratization of advanced NLP capabilities, empowering researchers and developers with limited resources.
The Future Role of NLP in Society
NLP is poised to become an increasingly integral part of our daily lives. We can anticipate a future where NLP-powered systems seamlessly integrate into various aspects of our society, from personalized education and healthcare to enhanced customer service and more efficient governance. For example, virtual assistants will become more sophisticated, capable of understanding nuanced human language and performing complex tasks, while AI-driven chatbots will provide 24/7 customer support across multiple platforms.
Furthermore, NLP will play a crucial role in making information more accessible, translating languages in real-time and providing personalized summaries of complex documents.
Addressing Global Challenges with NLP
NLP holds immense potential for tackling some of the world’s most pressing challenges. In healthcare, NLP can be used to analyze medical records, identify potential risks, and personalize treatment plans. For instance, NLP algorithms can analyze patient data to predict the likelihood of developing certain diseases, enabling early intervention and potentially saving lives. In environmental conservation, NLP can help analyze vast amounts of data from various sources (satellite imagery, scientific publications, social media) to monitor deforestation, predict natural disasters, and optimize resource management.
Furthermore, NLP can be instrumental in combating misinformation and promoting global understanding by automatically detecting and flagging fake news and providing accurate, multilingual information to diverse populations. The potential applications are vast and far-reaching, promising a future where technology empowers us to address complex global issues more effectively.
Illustrative Example: Sentiment Analysis
Sentiment analysis, also known as opinion mining, is a natural language processing technique used to automatically determine the emotional tone behind a piece of text. This can range from positive to negative, or even encompass more nuanced sentiments like joy, anger, or sadness. The process involves several key steps, from preparing the raw data to training a model capable of classifying new, unseen text.Sentiment analysis offers valuable insights across various domains, providing businesses with crucial feedback on products, services, and brand perception.
Understanding customer sentiment can inform strategic decision-making and enhance customer experience. This example will walk through the process using a simplified approach.
Data Preprocessing
The first step in sentiment analysis involves preparing the text data for processing. This crucial stage cleanses the raw text, making it suitable for analysis. This typically involves several sub-steps:
- Text Cleaning: This includes removing irrelevant characters (like punctuation marks), converting text to lowercase, and handling HTML tags or URLs if present. For instance, a review like “This product is AMAZING!!! I love it! 5 stars!!!” would be cleaned to “this product is amazing i love it 5 stars”.
- Tokenization: This involves breaking down the text into individual words or phrases (tokens). The cleaned example above would be tokenized into [“this”, “product”, “is”, “amazing”, “i”, “love”, “it”, “5”, “stars”].
- Stop Word Removal: Common words like “the,” “a,” “is,” and “are” (stop words) often don’t contribute much to sentiment, so they are removed. This reduces noise and improves efficiency. Our example would lose words like “is” and “it”.
- Stemming/Lemmatization: This reduces words to their root form (stemming) or dictionary form (lemmatization). “Amazing” might become “amaz” (stemming) or “amaze” (lemmatization). This helps group similar words together.
Feature Extraction
After preprocessing, features need to be extracted from the text to represent it numerically for the machine learning model. A common approach is to use a bag-of-words model.This model represents a text as a vector where each element corresponds to a word in the vocabulary, and the value represents the frequency of that word in the text. For example, the phrase “good product, great service” might be represented as: “good”:1, “product”:1, “great”:1, “service”:1.
More sophisticated methods, such as TF-IDF (Term Frequency-Inverse Document Frequency), can also be used to weigh words based on their importance across the entire dataset.
Model Training: Naive Bayes
The Naive Bayes algorithm is a simple yet effective probabilistic classifier suitable for sentiment analysis. It assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature. This “naive” assumption simplifies calculations but still often yields good results.Training a Naive Bayes model involves calculating the probability of each word belonging to a positive or negative class based on a labeled training dataset (reviews labeled as positive or negative).
The model then uses Bayes’ theorem to predict the sentiment of new, unseen text by calculating the probability of it belonging to each class based on the word frequencies.
Hypothetical Scenario: Analyzing Customer Reviews
Imagine an online retailer selling handmade jewelry. They’ve collected 1000 customer reviews. These reviews vary widely in sentiment, from enthusiastic praise to harsh criticism. Using sentiment analysis, the retailer can gain valuable insights.The retailer preprocesses the reviews (as described above), trains a Naive Bayes model using a subset of the reviews labeled as positive or negative by human reviewers.
The model then analyzes the remaining unlabeled reviews. The results might show that 70% of reviews are positive, 20% are negative, and 10% are neutral. The retailer can then delve deeper, analyzing negative reviews to identify recurring themes (e.g., complaints about shipping times or product quality). This allows them to address specific customer concerns and improve their products and services.
For example, frequent complaints about slow shipping might lead them to explore faster shipping options or improve their communication with customers about shipping times. Positive reviews, on the other hand, could highlight popular product features or aspects of the customer service that are working well.
Ultimate Conclusion
In conclusion, Natural Language Processing (NLP) represents a dynamic and rapidly evolving field with transformative potential across numerous sectors. While challenges remain, particularly concerning bias and ethical implications, ongoing advancements in deep learning and related areas promise even more sophisticated and impactful applications. The ability of NLP to bridge the gap between human communication and machine understanding opens exciting avenues for innovation, efficiency, and problem-solving across diverse industries, ultimately shaping a future where human-computer interaction becomes increasingly seamless and intuitive.
Key Questions Answered
What are the limitations of current NLP systems?
Current NLP systems struggle with nuanced language, sarcasm, ambiguity, and context-dependent meanings. They can also be susceptible to biases present in their training data, leading to inaccurate or unfair outputs.
How is NLP used in search engines?
NLP powers search engine functionalities like query understanding, relevance ranking, and information retrieval. It helps search engines interpret user queries, identify s, and deliver the most relevant results.
What is the difference between NLP and machine learning?
Machine learning is a broader field encompassing algorithms that allow computers to learn from data. NLP is a subfield of AI and machine learning specifically focused on enabling computers to understand and process human language.
What programming languages are commonly used in NLP?
Python is the most popular language for NLP due to its rich ecosystem of libraries like NLTK, spaCy, and TensorFlow.
What are some emerging trends in NLP?
Emerging trends include advancements in multimodal learning (combining text with images or audio), explainable AI (making NLP models more transparent), and the development of more robust and ethical NLP systems.